May 1, 20256 min read
Algorithms for Scalable ANN Search
Junior thesis with Prof. Robert Tarjan on approximate nearest neighbor search and hierarchical vector retrieval algorithms.

The project is a study of approximate nearest neighbor search, the problem of retrieving the points in a large high-dimensional collection that sit closest to a query. It pairs a careful theoretical treatment of the Hierarchical Navigable Small World algorithm with a hand-written C++ implementation, and then adds two original optimizations whose benefits are proven on paper and measured against the leading libraries.
The problem
Modern machine learning turns images, text, and other data into vectors called embeddings, arranged so that semantically similar inputs land close together. A simple bag-of-words construction already shows the idea, with shared tokens lighting up shared coordinates.
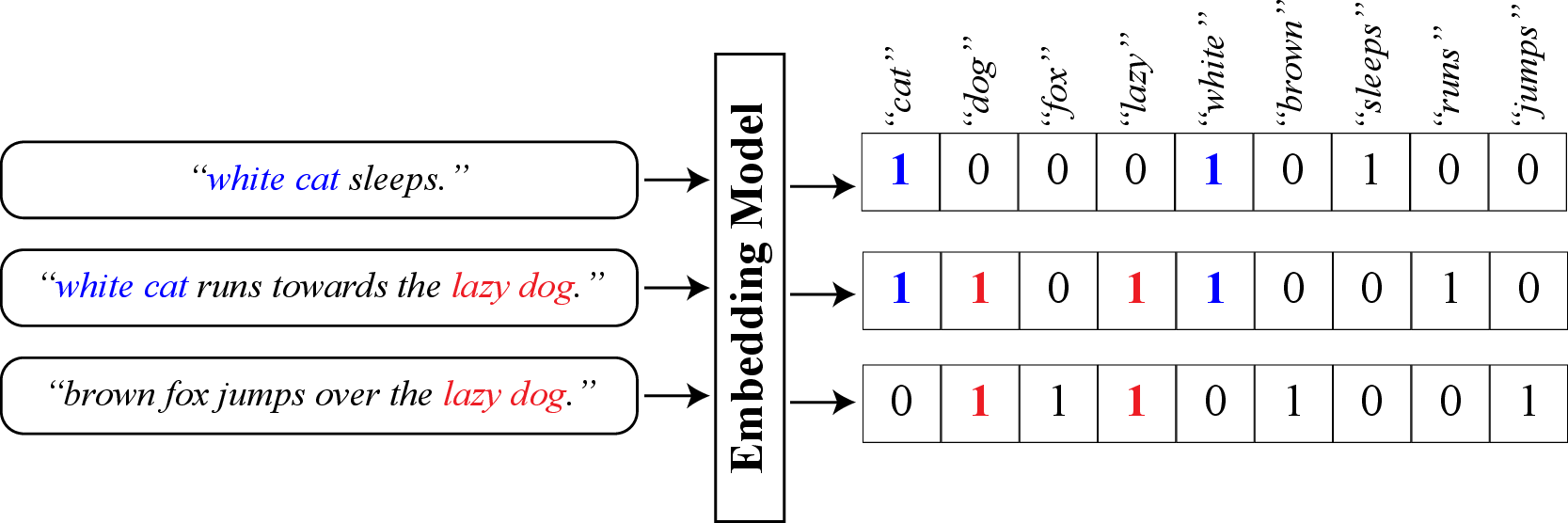
A bag of words embedding. Shared tokens activate shared dimensions, so semantic similarity turns into geometric proximity.
Retrieval then becomes a geometric question, namely finding the k nearest vectors to a query under a distance such as the Euclidean or the cosine metric. In high dimensions an exact answer is hopeless, because distances concentrate and almost every point looks equidistant from the query, which is the curse of dimensionality. The standard escape is to accept an approximate answer. A returned point is good enough when
for a small tolerance epsilon, where the starred point is the true nearest neighbor. Quality is then measured by recall, the fraction of the true neighbors that the search actually returns,
and every method is judged on the trade-off between recall and queries per second.
The Hierarchical Navigable Small World algorithm
HNSW organizes the data into a stack of proximity graphs. The bottom layer holds every point, and each higher layer keeps a random thinning of the one below, so a search can take long strides at the top and short careful steps at the bottom. Each point is assigned a level drawn from a geometric distribution, which gives
The thesis works through this structure in full and proves the costs that make the method attractive. A single insertion takes expected time of order log N, building the whole index takes order N log N, and a query runs in
where ef is the exploration factor that widens the final search. To check that these bounds describe the actual code rather than the idealized algorithm, the C++ engine was timed on synthetic data ranging from ten thousand up to ten million vectors. Plotting construction time against N log N gives a straight line, which is exactly the signature of the proven bound.
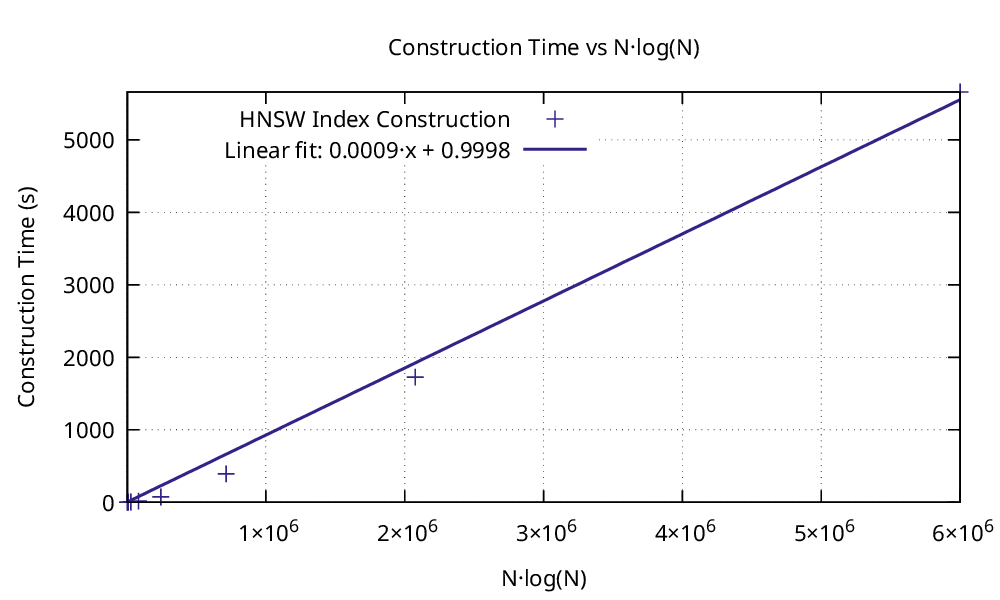
Index construction time plotted against N log N. The near perfect straight line confirms the order N log N construction cost proven for the algorithm.
Robust pruning with a spanner guarantee
In dense regions a node can collect many redundant neighbors, which wastes memory and slows the search down. The first optimization removes the edge from a node v to a candidate u whenever some other candidate w is a better stepping stone, that is whenever
for a tunable parameter alpha greater than one. The contribution here is a guarantee rather than a heuristic. The pruned graph is shown to be a spanner of the original, meaning the shortest path between any two nodes grows by at most a factor of
so that choosing alpha equal to one plus two over epsilon turns this into a clean spanner with stretch at most one plus epsilon. The parameter therefore dials the balance between a sparser graph and tighter distances, with a known worst case stretch.
The experiments trace this trade-off directly. Pruning too hard at alpha equal to 1.25 discards too much structure and recall collapses, while gentle pruning around alpha equal to five keeps recall above ninety percent and stays fast.
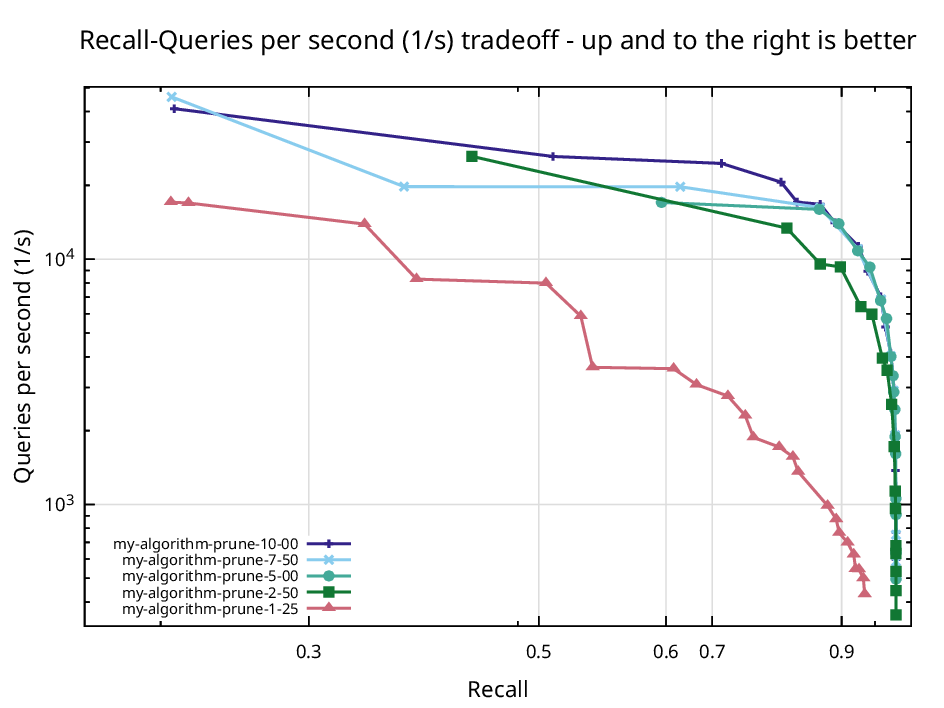
Recall against queries per second on GloVe-25 for several pruning strengths. Aggressive pruning at alpha 1.25 collapses recall, while alpha 5 sits at the upper right with the best balance.
Fixed at alpha equal to five, the pruned graph was compared against the three most used HNSW libraries, hnswlib, FAISS, and Vespa. Across GloVe, SIFT, and Fashion-MNIST it lands above and to the right of all of them, which is the favorable corner of the recall against speed plot.
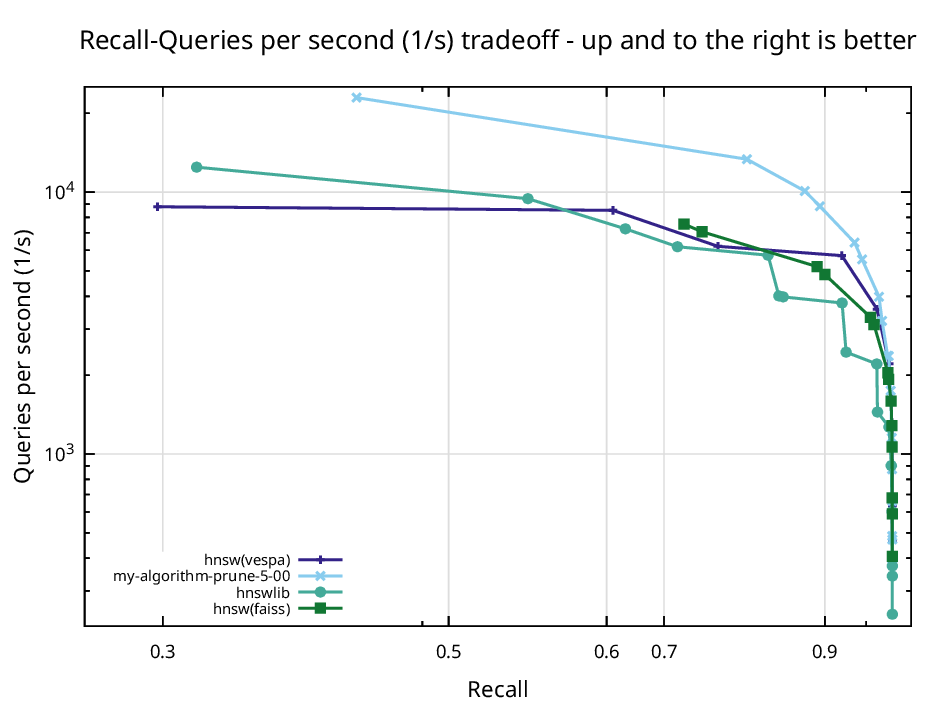
Recall against queries per second on SIFT-128 with alpha set to five. The pruned graph lands above and to the right of hnswlib, FAISS, and Vespa.
Dimension reduction by random projection
The upper layers of the index hold few points but still pay for distance computations in the full dimension. The second optimization compresses each upper layer with its own random projection, following the Johnson-Lindenstrauss lemma. A layer holding n points is projected down to
coordinates with a Gaussian matrix, which preserves every pairwise distance up to a small factor,
Because the upper layers shrink geometrically, the projected dimension quickly falls to a few dozen, so routing through the coarse layers follows nearly the same path at a fraction of the arithmetic cost. On Fashion-MNIST, whose vectors carry 784 dimensions, a distortion of epsilon equal to 0.6 proved to be the sweet spot, faster than a gentler setting that barely compresses and more accurate than an aggressive one that loses the route. Against the same three libraries the reduced index wins clearly in the medium recall and high throughput regime.
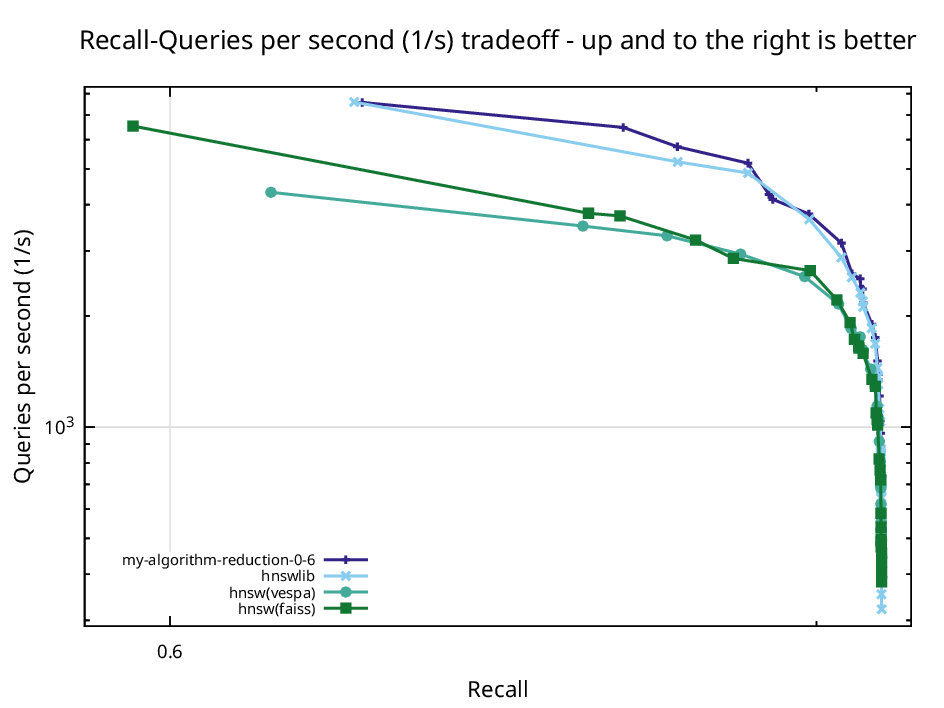
Recall against queries per second on Fashion-MNIST with the Johnson Lindenstrauss reduction at epsilon 0.6, compared against hnswlib, FAISS, and Vespa.
Outcome
The work delivers a HNSW engine that reproduces its proven logarithmic behavior in practice, together with two optimizations that each move the recall against speed frontier in a measurable way. The robust pruning carries a formal spanner guarantee and beats the leading libraries across several benchmarks, while the layer-wise projection trades a little accuracy at the very top of the recall range for a worthwhile gain in throughput. The implementation and full writeup are available on GitHub.
The Princeton Computer Science department recognized this work with its Outstanding Computer Science Independent Work Prize, one of seven such awards given that year. The degree was completed with Highest Honors and election to the Sigma Xi research honor society.